Салимóненко Дмитрий Александрович

Задание 1: Автоматизированное тестирование программ
(C, Linux)
СОДЕРЖАНИЕ
- Введение
- 1. Создаем информационные модели системной оболочки
- 1.1. Структурная модель
- 1.2. Функциональная модель IDEF0
- 1.3. Поведенческая (событийная) модель IDEF3
- 1.4. Методология DFD
- 1.5. Диаграмма деятельности программы (Activity Diagram)
- 2. Структурирование информации
- 2.1. Структурирование входных данных
- 2.2. Обозначение возможных ошибок во входных данных
- 2.3. Составление массива тестовых данных
- 2.3.1. Способ эквивалентности
- 2.3.2. Способ граничных значений
- 2.3.3. Способ диаграмм причин-следствий
- 2.3.4. Нагрузочное (стрессовое) тестирование
- 2.3.5. Тестирование производительности
- 2.3.6. Подготовка данных для тестирования
- 3. Разработка системы тестирования
- 3.1. Файлы проекта
- 3.2. Программные коды
Введение
Нужно будет написать, своего рода, программную оболочку – систему тестирования, которая позволит запускать и тестировать другую программу путем имитации действий пользователя. В качестве последней может фигурировать, например, программа, написанная в процессе изучения курса «Операционных систем», т.е. системная оболочка. Главное, чтобы программа не была совсем уж примитивной и позволяла вводить ряд параметров.
Тестирование будем проводить методом черного ящика (функциональное тестирование). Способы тестирования:
- Эквивалентности,
- Граничных значений,
- Диаграмм причин-следствий,
- Нагрузочное (стрессовое) тестирование,
- Тестирование производительности (скорости выполнения соответствующей операции, например, операции копирования файла).
Запуск системной оболочки можно производить программно при помощи одной из функций семейства exec() (см. ниже).
1. Создаем информационные модели системной оболочки
Модели следует разрабатывать в состоянии «Как Есть» («As Is»). Следует создавать не просто некие общие схемы, а именно – РЕАЛЬНЫЕ МОДЕЛИ программы (системной оболочки). Все модели следует сделать в одном из известных Вам программных продуктов, например, в программе IDEF, Ramus Educational, MS Office Visio или т.п. Должны быть оформлены, как полагается, должны присутствовать ВСЕ надписи, названия моделей и др.
В учебных целях, мы с Вами поступим так: не программу будем писать по готовым информационным моделям, а, наоборот, для готовой программы создадим информационные модели.
В процессе разработки моделей у Вас получатся рисунки и таблицы. Все они должны иметь соответствующий номер и название (например, Рис. 1. Информационная модель IDEF0).
1.1. Структурная модель
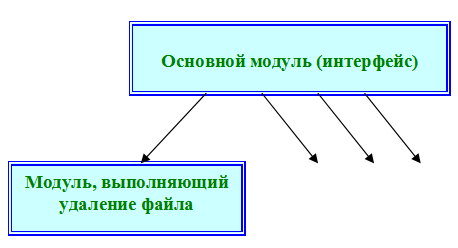
Вначале реализуем структурную модель системной оболочки. Она должна представлять собой структурную совокупность компонентов (модулей), составляющих ее. В качестве примера я приведу лишь часть, Вы же должны дополнить модель до состояния, полностью соответствующего программе.
Примечание: здесь и далее, если не будет оговорено особо, под словом «программа» будет восприниматься системная оболочка, выполненная Вами в процессе изучения курса «Операционные системы».
Итак, частичная структурная модель может иметь примерно следующий вид.
1.2. Функциональная модель IDEF0
Родительскую диаграмму А0 сделайте самостоятельно, ее я, в силу очевидности, опускаю. Далее будет декомпозиция родительской диаграммы примерно в следующем виде (см. ниже).
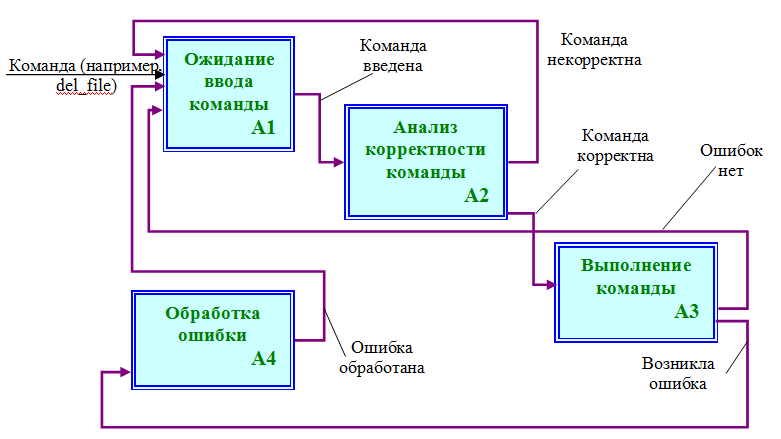
Точнее, приведена ее основная часть. Следует доработать эту модель с учетом, в частности, блока, отвечающего за первоначальный запуск программы. Кроме того, следует добавить:
- Исполнительные механизмы и управляющие воздействия,
- Дополнительные входные данные, в частности, имена файлов и/или каталогов, которые будут использованы в блоке
А3. Например, для выполнения копирования файла понадобятся два параметра: имена входного и выходного файлов, - Завершение работы программы при вводе команды вида «
exit». Появится соответствующая дополнительная стрелка результата («Останов»), выходящая из блокаА3.
Далее следует декомпозировать ВСЕ ТРЕБУЕМЫЕ (а не только один, как Вы делали ранее, в учебных целях, например, в курсе "Информационные системы и технологии") блоки в рамках декомпозиции 2-го уровня. В частности, блок А3 декомпозируется на соответствующее число блоков – модулей, каждый из которых выполняет какую-то одну операцию с файлами или каталогами (копирование, удаление, просмотр свойств и т.д.). Декомпозиция блока А3 будет носить параллельный характер.
Блок А3 следует декомпозировать с учетом вывода результата выполнения той или иной команды. Например, должны быть стрелки вида «Файл скопирован» и т.д., идущие в блок А1.
Декомпозицию 3-го уровня, по-видимому, делать нет необходимости, так как модули, выполняющие ту или иную работу с файлами или каталогами, являются простыми. Исключение составляет модуль, выполняющий копирование каталога, где применена рекурсия. Вот там бы целесообразно выполнить ее. Однако, если Вы считаете это необходимым, для целей наглядности, можете выполнить декомпозицию 3-го уровня и для всех остальных модулей.
Не забудьте, что если в программе (в модулях) делается вызов функции вывода ошибки при проверке выполнения той или иной функции, соответственно, должна быть индивидуальная стрелка в блок А4. Т.е. таких стрелок будет достаточно много, по числу вызовов функции обработки ошибок во ВСЕХ модулях. Т.е. декомпозиция 2-го уровня будет выглядеть достаточно сложно, по сравнению с 1-м уровнем.
Под анализом корректности команды имеется в виду ее синтаксис. Т.е. если пользователь, в процессе работы с оболочкой, ввел неверную команду, она считается некорректной и управление передается вновь на ожидание ввода команды.
1.3. Поведенческая (событийная) модель IDEF3
IDEF3-модели используются для документирования технологических (информационных) процессов, где важна последовательность выполнения процесса. Эта модель потребуется для исследования конкретных типов параметров, вводимых пользователем в процессе работы программы. Она может иметь примерно следующий вид:
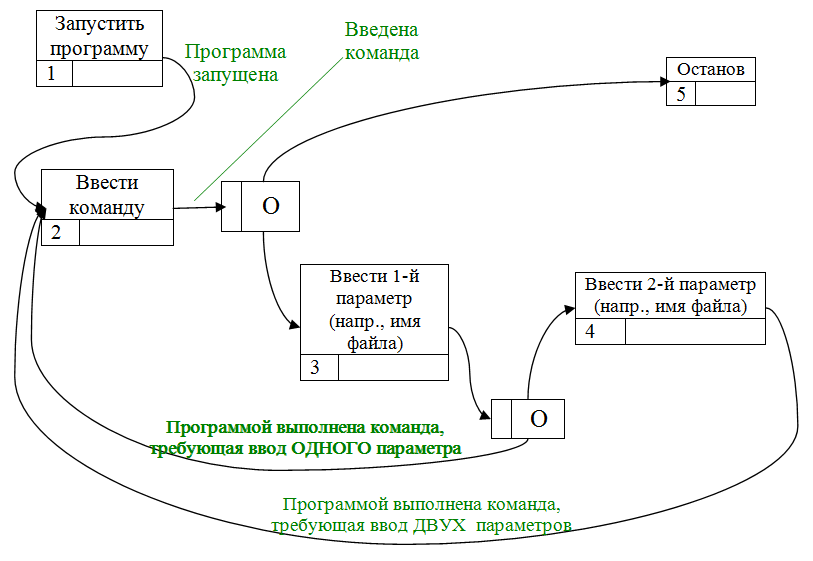
Эту модель следует дополнить результатами выполненных операций: «Команда введена», «Параметр введен». Они отображаются на модели IDEF3 в виде прямоугольников, содержащих в себе названия этих результатов, подключенными пунктирными линиями к нижним частям прямоугольников, обозначающих соответствующие работы (например, к прямоугольникам №2 и №3). Если это не совсем понятно, посмотрите примеры диаграмм IDEF3 в интернете.
Данная модель позволит Вам выявить, какие именно данные и на каком этапе работы программы требуется вводить пользователю (а, следовательно, и системе тестирования, которую Вам потребуется написать). Доработайте эту диаграмму.
Отметим, что в нашем случае данная диаграмма будет, по своему смыслу, несколько похожей на некоторые другие виды диаграмм, например, на диаграмму деятельности (Activity Diagram). Имеется в виду – диаграмму деятельности пользователя, а также DFD.
1.4. Методология DFD
Диаграммы потоков данных DFD позволяют эффективно и наглядно описать процессы документооборота и обработки информации. Могут использоваться две нотации: Йордана и Гейна-Сарсона. Вы можете использовать любую из них (они незначительно отличаются в обозначениях).
По сути, в данном случае DFD-диаграмма будет похожа на диаграмму IDEF3. Отличие, разве что, в оформлении. Для тренировки, выполните DFD-диаграмму. Я ее приводить не буду, в силу аналогичности.
1.5. Диаграмма деятельности программы (Activity Diagram)
Смысл ее немного похож на IDEF3, однако, содержит горизонтальную разбивку по участникам выполнения процессов. В данном случае будут присутствовать следующие участники:
- Пользователь (или тестирующая система),
- Меню (модуль, ожидающий ввода команды),
- Исполняющие модули (выполняющие операции копирования файла, удаления файла и т.д.). Следует перечислить все исполняющие модули,
- Модуль обработки ошибок.
Данная диаграмма будет иметь примерно следующий вид:
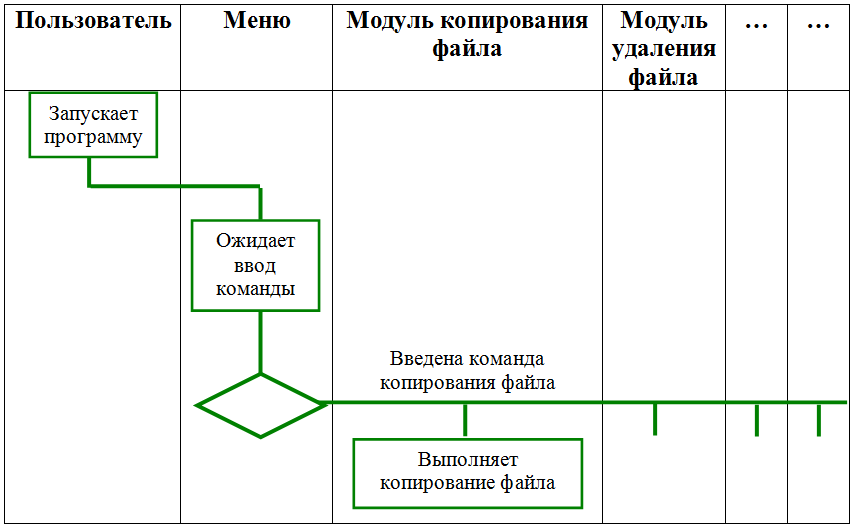
Здесь в форме ромба обозначен множественный (а не бинарный, как обычно) выбор между вариантами введенной команды. Эту диаграмму следует дополнить. Не забудьте, в частности, о возможности ввода неверной команды, команды выхода, а также модуль-обработчик ошибок. Кроме того, следует дополнить эту диаграмму также и переходом в состояние ожидания ввода команды после того, как выполнится соответствующая команда или произойдет обработка ошибки.
2. Структурирование информации
Таким образом, если Вы детально и правильно реализуете рассмотренные выше модели, Вы получите в распоряжение обобщенный набор возможных входных данных для программы, а также перечень возможных результатов.
2.1. Структурирование входных данных
В качестве входных данных могут фигурировать:
1) Название команды,
2) Имена файлов или каталогов.
Следует составить таблицу-перечень входных данных примерно в следующем виде:
| Входные данные | Названия команд | Названия файлов, каталогов |
| Точный или примерный синтаксис |
Точный синтаксис: Del_file, Copy_file, …. |
Примерный синтаксис: File.txt, файл, Файл1.doc |
| Число вариаций синтаксиса | Указать точное число команд | Не ограничено |
| Возможные вводимые пользователем символы | Любые символы, вводимые с клавиатуры | Любые символы, вводимые с клавиатуры |
| … |
Подумайте, какими еще актуальными, для целей последующего тестирования, характеристиками можно было бы дополнить эту таблицу. Это может быть, например, их размер, кодировка(?)…
2.2. Обозначение возможных ошибок во входных данных
Ошибки во входных данных могут быть внесены пользователем как умышленно, так и случайно. Это означает, что на любом этапе работы программы возможен ввод самых разных данных, любой длины.
Следует продумать, какие могут возникнуть проблемы в связи с этим. Например:
- Переполнение буфера при ввода данных слишком большого размера,
- Неверное срабатывание программы при вводе некоторых данных, с виду кажущихся корректными,
- …
Их следует выявить и перечислить в виде таблицы с кратким обоснованием возможных последствий каждой из них, с указанием команды языка С/С++, выполнение которой может вызвать проблему. Проблемы могут быть, как минимум, трех видов:
- Возникновение сообщения об ошибке с сохранением работоспособности программы,
- Некорректное выполнение программы без сообщений об ошибках,
- Аварийное прерывание работы программы.
Таблица должна иметь примерно следующий вид:
| Вид проблемы | Последствие | Критичность |
Переполнение буфера при выполнении команды open() |
Аварийное прерывание программы | Высокая |
| Ошибка при открытии несуществующего файла | Вывод сообщения об ошибке | Отсутствует |
| … | … | … |
2.3. Составление массива тестовых данных
Для целей тестирования программы необходим массив входных данных, который как раз и будет содержать, в том числе, такие данные, которые способны вызвать проблемы в работе программы. Такой массив может быть составлен на основе результатов структурирования информации, проведенного выше.
В первую очередь, так как вводимые пользователем данные могут иметь произвольный вид, следует составить несколько случайных наборов, состоящих из различных групп символов:
- Цифры,
- Латинские буквы,
- Русские буквы,
- Специальные символы.
Набор может иметь вид, например:
4j6*(ощп-ty
Далее составляем наборы данных, исходя из обозначенных выше способов тестирования.
2.3.1. Способ эквивалентности
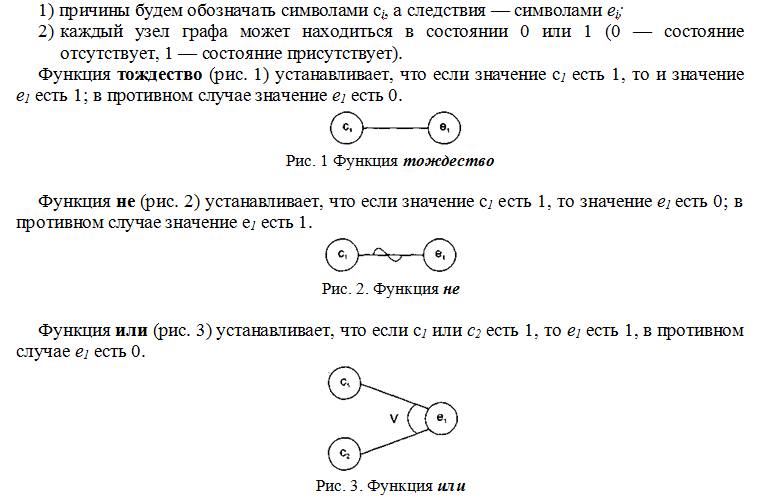
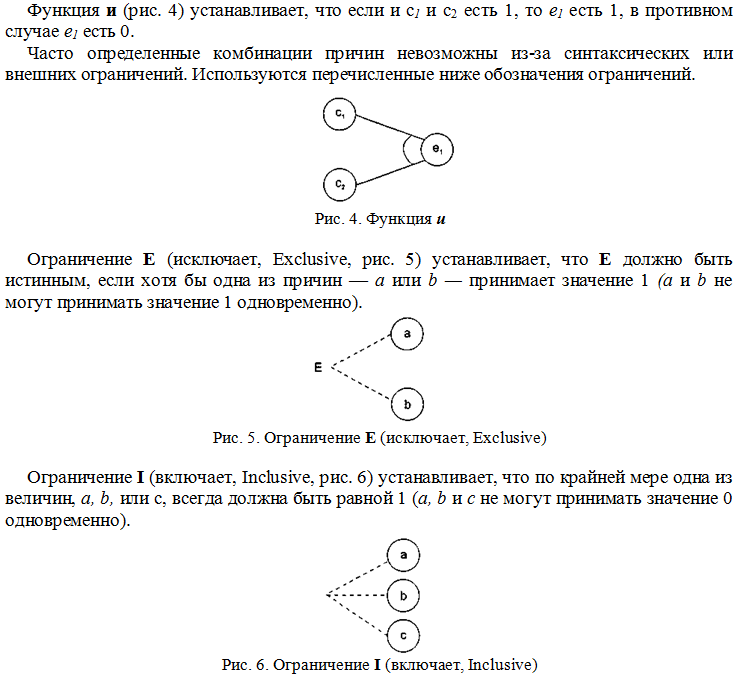
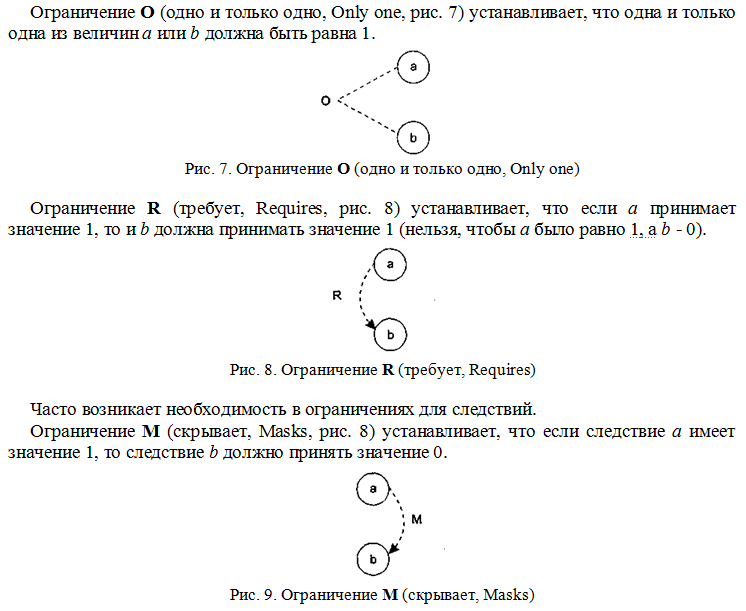
Выявляем недопустимые классы данных:
- Все данные, которые содержат специальные символы, которые НЕ МОГУТ содержаться в имени файла или каталога в операционной системе Linux (символы
* ? /) и т.д. Для этой цели следует самостоятельно выяснить – какие именно символы являются, в данном случае, недопустимыми, - Все данные, которые имеют количество байт (или символов) более, чем (…).
Подумайте, существуют ли еще какие-либо классы данных. Является ли имя файла, не содержащего недопустимых символов, но при этом такого файла не существует в файловой системе, допустимым именем для нашей программы?
Таким образом, определяем ВСЕ допустимые и недопустимые классы данных (следует их определить и описать). После чего следует изобразить их в виде рисунка совокупности множеств.
Наконец, следует сформировать наборы данных – по несколько штук для каждого класса. Например, допустимый класс:
йцукен; qwertyui; …
Готовые наборы данных для последующего тестирования следует занести в таблицу вида
| Класс | Описание | Примеры наборов данных |
| Допустимый | Цифры, символы кириллицы и латинские |
йцукен qwertyui 12ва |
| Недопустимый по причине наличия специальных символов | … | … |
| Недопустимый вследствие превышения максимального числа байт (символов) | … | … |
| … | … | … |
2.3.2. Способ граничных значений
В данном случае следует проконтролировать максимальную границу размера данных в символах (байтах). Допустим, она составляет 1000. Стало быть, граничными значениями здесь будут данные, содержащие 999, 1000 и 1001 символ (байт). Конкретную границу по каждому типа данных определите самостоятельно, с учетом особенностей программы и операционной системы Linux.
Обращаю внимание: данные следует брать только из допустимого класса, так как недопустимые уже не используются в силу предыдущего пункта (см. п.2.3.1.).
Также следует разработать наборы данных, содержащих имена несуществующих объектов файловой системы. Т.е. это имена файлов, каталогов, которых нет.
2.3.3. Способ диаграмм причин-следствий
Предварительно следует построить соответствующую диаграмму. Пример из учебника С.А. Орлова «Технологии разработки программного обеспечения» выглядит следующим образом. Пусть программа выполняет расчет оплаты за электричество по среднему или переменному тарифу.
При расчете по среднему тарифу:
- при месячном потреблении энергии меньшем, чем 100 кВт/ч, выставляется фиксированная сумма;
- при потреблении энергии большем или равном 100 кВт/ч применяется процедура А планирования расчета.
При расчете по переменному тарифу:
- при месячном потреблении энергии меньшем, чем 100 кВт/ч, применяется процедура А планирования расчета;
- при потреблении энергии большем или равном 100 кВт/ч применяется процедура В планирования расчета.
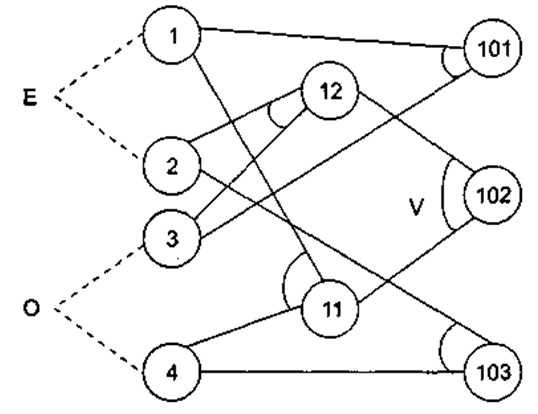
Шаг 1. Причинами являются:
1) расчет по среднему тарифу;
2) расчет по переменному тарифу;
3) месячное потребление электроэнергии меньшее, чем 100 кВт/ч;
4) месячное потребление электроэнергии большее или равное 100 кВт/ч.
На основе различных комбинаций причин можно перечислить следующие следствия:
- 101 — минимальная месячная стоимость;
- 102 — процедура А планирования расчета;
- 103 — процедура В планирования расчета.
Шаг 2. Разработка графа причинно-следственных связей (см. рисунок).
Узлы причин перечислим по вертикали у левого края рисунка, а узлы следствий — у правого края рисунка. Для следствия 102 возникает необходимость введения вторичных причин — 11 и 12, — их размещаем в центральной части рисунка.
Шаг 3. Генерация таблицы решений. При генерации причины рассматриваются как условия, а следствия — как действия.
Порядок генерации.
- Выбирается некоторое следствие, которое должно быть в состоянии «1».
- Находятся все комбинации причин (с учетом ограничений), которые устанавливают это следствие в состояние «1». Для этого из следствия прокладывается обратная трасса через граф.
- Для каждой комбинации причин, приводящих следствие в состояние «1», строится один столбец.
- Для каждой комбинации причин доопределяются состояния всех других следствий. Они помещаются в тот же столбец таблицы решений.
- Действия 1-4 повторяются для всех следствий графа.
Таблица решений для нашего примера показана в таблице ниже.
Шаг 4. Преобразование каждого столбца таблицы в тестовый вариант. В нашем примере таких вариантов четыре.
Тестовый вариант 1 (столбец 1) ТВ1:
ИД: расчет по среднему тарифу; месячное потребление электроэнергии 75 кВт/ч.
ОЖ.РЕЗ.: минимальная месячная стоимость.
Тестовый вариант 2 (столбец 2) ТВ2:
ИД: расчет по переменному тарифу; месячное потребление электроэнергии 90 кВт/ч.
ОЖ.РЕЗ.: процедура A планирования расчета.
Тестовый вариант 3 (столбец 3) ТВЗ:
Граф причинно-следственных связей
ИД: расчет по среднему тарифу; месячное потребление электроэнергии 100 кВт/ч.
ОЖ.РЕЗ.: процедура А планирования расчета.
Тестовый вариант 4 (столбец 4) ТВ4:
ИД: расчет по переменному тарифу; месячное потребление электроэнергии 100 кВт/ч.
ОЖ.РЕЗ.: процедура В планирования расчета.
Таблица решений для расчета оплаты за электричество
| Номера столбцов (наборов тестовых вариантов) — > | 1 | 2 | 3 | 4 | ||
| Условия | Причины | 1 | 1 | 0 | 1 | 0 |
| 2 | 0 | 1 | 0 | 1 | ||
| 3 | 1 | 1 | 0 | 0 | ||
| 4 | 0 | 0 | 1 | 1 | ||
| Вторичные причины | 11 | 0 | 0 | 1 | 0 | |
| 12 | 0 | 1 | 0 | 0 | ||
| Действия | Следствия | 101 | 1 | 0 | 0 | 0 |
| 102 | 0 | 1 | 1 | 0 | ||
| 103 | 0 | 0 | 0 | 1 | ||
На основе этого примера нужно будет составить аналогичные граф и таблицу для нашей программы. В качестве причин здесь будут выступать:
- 1 - Ввод команды копирования файла,
- 2 - Ввод команды удаления файла,
- 3 - Ввод имени исходного файла,
- 4 - Ввод имени конечного файла,
- . . .
Нужно выделить группы причин, по аналогии с графом на рисунке. Скорее всего, будет три таких группы: команды, исходные имена объектов файловой системы (файлов, каталогов), конечные имена объектов. Следствиями будут:
- 101 - Копирование исходного файла в конечный,
- 102 - Удаление файла с исходным именем,
- . . .
Следует подумать - будут ли присутствовать причины 2-го и более высоких порядков.
2.3.4. Нагрузочное (стрессовое) тестирование
Вообще, нагрузочное тестирование – тема достаточно обширная. В нашем случае, в учебных целях, можно инициировать запуск нашей программы ОДНОВРЕМЕННО множество раз от имени одного и того же пользователя. На практике для этой цели можно использовать множественные вызовы соответствующей нашим целям функции из семейства exec() при помощи функции fork(), которая, как известно, порождает клоны процессов. Как Вы помните, использование этой функции мы уже изучали на примере одной из программ-серверов на ТСР-сокетах.
Примечание. Имейте в виду, что бесконтрольное применение функции fork() может породить, как минимум, зависание операционной системы, а то и ее порчу. Поэтому целесообразно ограничить максимальное количество одновременно запускаемых клонов программы число, равным, например, 1000. Тем самым мы, в случае успешного прохождения теста, выявим. как минимум, 1000-кратный уровень устойчивости по нагрузке.
2.3.5. Тестирование производительности
Речь идет о тестировании времени выполнения программы при ПРОГРАММНОМ (не ручном!) вводе параметров – входных данных. Это делается очень просто: считывается текущее время начала и конца выполнения программы в каждой итерации (см. блоки А1…А3(А4) по модели IDEF0, см. п.1.2) и затем определяется их разница.
Тестирование производительности целесообразно проводить в совокупности с нагрузочным тестированием (см. п. 2.3.4.). Очевидно, при росте нагрузки производительность будет снижаться. Следует провести тестирование при наиболее характерных уровнях нагрузки, выражаемой, в данном случае, количеством одновременно запущенных клонов программы. Например, это могут быть количества, равные 1, 10, 50, 100, 500, 1000.
Следует построить график зависимости производительности (времени выполнения) от уровня нагрузки.
Примечание: этот график можно выполнить вручную. Хотя, по возможности, лучше бы использовать какую-либо графическую библиотеку.
2.3.6. Подготовка данных для тестирования
После того, как будут готовы массивы данных для тестирования, их следует занести в текстовый файл. Этот файл должен считываться системой тестирования.
3. Разработка системы тестирования
После чего необходимо написать систему для тестирования, которая будет запускать нашу программу и, имитируя действия пользователя, задавать ей считываемые из файла входные данные. По сути, это будет небольшая программка, запускающая нашу программу (системную оболочку) и задающую ей, в процессе запуска, те или иные параметры из наборов, содержащихся в указанном выше файле.
3.1. Файлы проекта
В состав программных модулей должны входить:
- Системная оболочка (она будет тестироваться),
- Система тестирования
test1_pi.cpp, - Отладочная программа
test_PI.cpp(временно, только для отладки предыдущей программы), - Файл с наборами тестовых значений.
Система тестирования будет считывать, в цикле, наборы тестовых данных из файла (построчно) и, считая их число, должна запускать, в виде дочернего процесса, системную оболочку и передавать ей эти данные в качестве параметров ввода. После чего должен проводиться анализ факта прохождения теста по двухбалльной шкале:
- Тест пройден,
- Тест не пройден.
3.2. Программные коды
Небольшая сложность состоит в том, что, после запуска программы, параметры должна вводиться не единовременно, а в два или три этапа – в зависимости от того, каким был выбран первый параметр, характеризующий название выполняемой команды – например, Copy_file – копирование файла; конечно, у Вас может быть какое-то свое, другое название. Т.е. вначале Вы вводите Copy_file. Нажимаете Enter. Затем – вводите имя исходного файла. И, наконец, имя конечного файла. Следует продумать, каким образом при этом возможно осуществить программный (без участия пользователя) многоэтапный ввод входных данных.
Что касается системы тестирования, для этого можно использовать функцию exec(). Обоснуйте выбор конкретной функции из приведенного по ссылке семейства. На мой взгляд, наиболее подходящей здесь является функция
int execvp(char *fname, char *arg[ ])
Следует иметь в виду, что при возникновении аварийных ситуаций в тестируемой программе (например, в случае ошибок сегментации) последняя будет аварийно завершена, а с ней, возможно, и сама тестируемая система. Подумайте, как можно было бы повысить ее отказоустойчивость. Если сможете – реализуйте это. Поможет ли в этом организация дочерних процессов функцией fork()?
Исходный код тестовой системы, запускающей программу (системную оболочку), может иметь, для начала, следующий вид:
- // Листинг test1_pi.cpp
- #include <sys/wait.h>
- #include <stdlib.h>
- //#include <stdio.h>
- #include <errno.h>
- #include <unistd.h>
- #include <iostream>
- using namespace std;
- int main(int argc, char * argv[])
- { int pid, status;
- // if (argc < 2) {
- // printf(" Too few arguments);
- // return EXIT_FAILURE;
- // }
- printf("Starting %s...\n", argv[0]);
- // Запасаем параметр ввода - строку "LINE" в качестве содержимого буфера ввода (STDIN) для программы test_PI.c. Т.е. значение в буфере ввода будет уже готово и оно будет ожидать, до тех пор, пока какая-нибудь программа не потребует ввести данные (с консоли), например, при помощи функции cin>>
- string test_param_s = "echo \"LINE\" | ./test_PI";
- test_param_s = "echo ";
- test_param_s += argv[1]; // Вместо argv[1] следует считать параметр набора тестовых данных из соответствующего файла
- test_param_s += " | ./test_PI";
- char* test_param = (char*)test_param_s.c_str();
- // Создаем массив значений для функции execvp()
- char* xar[] = {"sh", "-c", test_param, NULL};
- string str = "sh"; // В языке С было бы не string, а char*
- char* strcha = (char*)str.c_str(); // Тоже, потому что у нас используется стандарт С++11 ANSI ISO
- pid = fork(); // Создаем дочерний процесс, дальше работает он
- if (pid == 0) {
- execvp(strcha, &xar[0]); // Меняем код дочернего процесса на код программы, имя которой содержится в strcha, дальше будет выполняться она уже в рамках дочернего процесса
- perror("execvp"); // Если вдруг дошли до этого места, следовательно, что-то пошло не так
- return EXIT_FAILURE;
- } else { // Когда дочерний процесс прекратит выполняться
- if (wait(&status) == -1) {
- perror("wait");
- return EXIT_FAILURE;
- }
- if (WIFEXITED(status))
- printf("Child terminated normally with exit code %i\n",
- WEXITSTATUS(status));
- if (WIFSIGNALED(status))
- printf("Child was terminated by a signal #%i\n", WTERMSIG(status));
- if (WCOREDUMP(status))
- printf("Child dumped core\n");
- if (WIFSTOPPED(status))
- printf("Child was stopped by a signal #%i\n", WSTOPSIG(status));
- }
- return EXIT_SUCCESS;
- }
Как видим, при помощи команды execvp() происходит не непосредственный вызов программы test_PI, а через оболочку (командный интерпретатор) sh. Дело в том, что если просто вызвать (при помощи execvp()) эту программу, не удастся передать ожидаемое ею значение. Потому как это - прерогатива устройства ввода, например, из bash (консоли). Однако, консоль открыта НЕ при помощи execvp(). Поэтому придется вначале загрузить "свой" командный интерпретатор, а ему уже передавать любые данные. Хотя, execvp() вполне может управлять работой открытой ранее консоли, выполнять системные команды; почему ее нельзя использовать для передачи параметров, перенаправления ввода-вывода - мне, честно сказать, непонятно. Видимо, это - запрет на уровне операционной системы, в целях безопасности.
Примечание: опция
-с используется для того, чтобы после выполнения работы командный интерпретатор автоматически выгружался, при этом мы вновь попадем в консоль - ту самую, из которой запустили программу test1_pi.cpp на выполнение.
В остальном, надеюсь, здесь все понятно. Пояснений требуют, разве что, строки 17…20. Там мы вначале запасаем строку вида
"echo \"LINE\" | ./test_PI"
Слово LINE лучше бы держать в кавычках. Но, так как кавычки будут содержаться внутри других кавычек, то их экранируем обратными слешами.
Это строка представляет собой не что иное, как shell-скрипт, который будет запущен командой execvp() – см. строку 28. Вначале этот скрипт подготавливает данные для ввода в устройстве STDIN (клавиатура+консоль). Как только какая-нибудь программа потребует данные из устройства ввода, они ему тотчас будут переданы. Таковой программой будет являться test_PI. А вертикальная черта служит для разделения команд между собой, т.е. для устройства конвейера. При этом выходные данные (OUTPUT) первой команды (которая слева) являются входными данными (INPUT) следующей команды (т.е. той, которая находится правее).
Итак, вначале в консоль (точнее, в устройство ввода) печатается слово LINE, затем, после запуска программы test_PI и после того, как она начнет ожидать ввода параметров с клавиатуры, устройство ввода автоматически передаст ей это слово. И дальше оно уже будет в распоряжении этой программы.
Для целей тренировки, в строке 19 вместо этого слова задается второй аргумент командной строки (первый параметр, идущий через пробел после имени программы при ее запуске). Например, если мы запустим программу test1_pi.cpp следующим образом:
./test1_pi 12345df
то уже параметр 12345df (а не LINE) попадет в функцию execvp(), а она передаст его, в свою очередь, программе test_PI.
Но, повторимся, это – лишь для тренировки. Необходимо будет сделать так, чтобы параметр этот считывался (в порядке итерации цикла) из файла, содержащего наборы тестовых данных (см. выше). Этот параметр может быть, в данном случае, именем команды, которую пользователь вводит в консоли при работе с системной оболочкой.
Вспомним, что, помимо команды, пользователь будет потом еще вводить другие параметры – имена файлов или каталогов (одно или два). Соответственно, следует предусмотреть в строке 17(18) возможность ввода не одного, а двух или трех параметров:
- Название команды системной оболочки - обязательно,
- Имя исходного файла (или каталога) - обязательно,
- Имя конечного файла – возможно.
Если третьего параметра нет, он должен иметь пустое значение или, что предпочтительнее, его вообще не должно быть в строке.
Для этого в команде echo следует предусмотреть переносы строк (\n) примерно следующим образом:
string test_param_s = "echo \"LINE1\"\n\"LINE1\"\n\"LINE1\" | ./test_PI";
Выяснить число параметров (2 или 3) можно после того, как будет прочитана очередная строка из файла с наборами тестовых значений, путем подсчета компонентов соответствующего набора. Это предлагаю выполнить самостоятельно.
Для отладки приведенного выше чернового варианта тестовой системы можно использовать, к примеру, следующий простой код:
- // test_PI.cpp
- #include <iostream>
- using namespace std;
- string funct();
- int main(void){
- int len = funct();
- cout<<len<<endl;
- }
- string funct() {
- cout<<"Введите что-нибудь в консоли и нажмите Enter:\n";
- cin>>data;
- int len = data.size();
- return len;
- }
Как видно, это программа ожидает ввода какой-нибудь строки и, после ввода, сразу же выводит эту строку в консоль. Система test1_pi автоматически «подсунет» этой программе строку (см. выше), после чего последняя. получив ожидаемый ввод значения, продолжит свою работу, а именно - выведет эту строку в консоль и закончит работу.
Эта программка приведена лишь для отладки системы тестирования. В частности, она позволит отработать автоматизированный ввод параметра (строки) системой тестирования. Следует ее немного усовершенствовать, чтобы она ожидала не один, а два или три параметра. После того, как Вы на этом простом примере отладите работу test1_pi (она также должна будет передавать 2 или 3 параметра), следует переходить уже к ее взаимодействию с системной оболочкой.
С уважением, Салимоненко Д.А.