Салимóненко Дмитрий Александрович

ЗАДАНИЕ 5: Разработка сервера на TCP-сокетах в LINUX
СОДЕРЖАНИЕ
- Введение
- I этап: Возврат заголовков браузера
- II этап. Открываем файл html
- Функция, читающая html-файл
- III этап. Основная часть программы, открывающей файл html
- Запускаем Эхо-сервер
- IV этап. Кодировки
- V этап. Формируем GET-запрос
- Формирование атрибута стиля тега абзаца
- Выводы
- Задание для самостоятельной разработки
Введение
Если Вы полностью освоили работу листингов, то Вашего объема понимания работы (на среднем уровне) сетей в операционной системе Linux вполне должно хватить, чтобы создать почти что «настоящий» сервер. Способный взаимодействовать не только с листингом-клиентом, но и, например, с браузером.
В этом задании Вам предстоит работать с ним локально, т.е., по сути. Вы его опробуете в качестве виртуального сервера. Виртуальный – это означает, что он будет (пока) работать на том же самом компьютере, что и клиент. Хотя, вполне можно запустить его, скажем, на одном из компьютеров локальной сети и взаимодействовать с ним, почти как с настоящим сервером. Можно также (с некоторыми ограничениями) запустить его и на каком-нибудь хостинге. Вдобавок к уже имеющемуся серверу.
Собственно, настоящий сервер, по сути, отличается лишь гораздо большей функциональностью, защитой от ненужных воздействий. А идея и принципы взаимодействия с клиентами – те же самые.
I этап: Возврат заголовков браузера
Рассмотрим простой сервер, который возвращает все то, что ему присылает браузер, плюс к тому – показывает счетчик обновлений страницы. Информация, отдаваемая браузеру, дублируется в консоли.
Вот код программы:
// Листинг 11. Виртуальный Эхо-сервер: получение и возврат заголовков браузера.
#include <sys/types.h>
#include <sys/socket.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <string.h>
char message1[] = "Server iteration: ";
char adding[8];
unsigned int sz;
int main()
{
int sock, listener;
struct sockaddr_in addr;
char buf[2048];
int bytes_read;
listener = socket(AF_INET, SOCK_STREAM, 0);
if(listener < 0)
{
perror("socket");
exit(1);
}
addr.sin_family = AF_INET;
addr.sin_port = htons(3425);
addr.sin_addr.s_addr = htonl(INADDR_ANY);
if(bind(listener, (struct sockaddr *)&addr, sizeof(addr)) < 0)
{
perror("bind");
exit(2);
}
listen(listener, 1);
int i =0; // Счетчик итераций сервера
while(1)
{i++;
sz=sizeof(addr);
sock = accept(listener, (struct sockaddr *)&addr, &sz );
printf ("\n");
if(sock < 0) {perror("accept"); exit(3);}
{
bytes_read = recv(sock, buf, 1024, 0);
strncat(buf, message1, sizeof(message1));
// Записываем целую переменную в область памяти типа char (иными словами, преобразуем int в char)
sprintf (adding, "%d", i);
// Дописываем в конец сообщения счетчик итераций сервера
strncat(buf, adding, strlen(adding) * sizeof(char));
//printf("buf= %lu \n", strlen(buf));
printf("buf= %s \n", buf);
send(sock, buf, bytes_read+sizeof(message1) + strlen(adding) * sizeof(char)-1, 0);
if(bytes_read <= 0) break;
memset (buf, 0, sizeof(buf));
}
close(sock);
}
return 0;
}
Компилируется программа обычным образом, примерно так:
gcc -o server server.c
В общем-то, программа напоминает Листинг 2 (из заданий по сокетам). Как обычно, сервер открывает сокет на прослушивание на порту 3425 для любых клиентов.
Примечание 1. Если сервер загружен локально (т.е. на локальном компьютере и/или в локальной сети, доступ к нему из глобальной сети (интернет), скорее всего, будет запрещен. Подумайте, почему. При каких условиях такой доступ будет, все-таки, возможен?
Примечание 2. Нет особой разницы, на каком из компьютеров локальной сети будет работать сервер: на локальном (т.е. на том. на котором запущен браузер) или на каком другом. Отличие лишь в том. что в адресной строке браузера вместо IP-адреса 127.0.0.1 нужно будет указать другой адрес – тот, который присвоен этому компьютеру.
Затем, открывает еще один сокет, который и используется для приема/передачи сообщений.
Как только какой-нибудь клиент (например, программа из Листинга 1 или браузер) отправляет серверу сообщение, он считывает его. Затем формирует ответ для клиента, добавляя в конец полученного сообщения символы "Server iteration: ", а также значение переменной i (предварительно преобразованное в формат char), являющееся счетчиком итераций цикла while.
После чего тут же происходит передача ответа сервера клиенту и переход на следующую итерацию цикла. Увеличивается счетчик итераций на 1, ну, и т.д.
Обратите внимание: почему в функции send в качестве числа передаваемых байтов указана сумма числа соответствующих байтов за вычетом 1?
Для обращения к серверу (который, естественно, должен быть предварительно запущен) можно использовать любой более-менее современный браузер. Так как сервер находится на том же самом компьютере, что и браузер, IP-адрес будет равным 127.0.0.1. Соответственно, в строке запроса (адресная или командная строка) браузера должно быть:
http://127.0.0.1:3425
Все, как обычно: протокол, двоеточия, два слеша, доменное имя (или IP-адрес) и, при необходимости, номер порта.
Примечание. Вы уже, естественно, знаете, что если не указать имя порта, то браузер пошлет запрос на стандартный порт по умолчанию, в данном случае – 80.
Итак, в браузере появятся заголовки его запроса (которые вернул обратно сервер), а также, через пустую строчку – символы:
Server iteration: Целое число
То же самое появится в консоли, через которую запущен сервер.
При обновлении страницы счетчик итераций будет последовательно увеличиваться, как в браузере, так и в консоли - синхронно.
II этап. Открываем файл html
Обычно, браузерами открывают файлы html, находящиеся (или формирующиеся «на лету») на серверах или локальных компьютерах.
Примечание. Даже если файл имеет расширение, например, php, asp или другое аналогичное, следует понимать, что браузеру в итоге передается, все-таки, файл html. Браузер НЕ МОЖЕТ самостоятельно обрабатывать программные файлы, типа рнр.
Все, что может браузер в этой связи – это указать соответствующие параметры запроса, при этом, быть может, запросив у сервера ту или иную вебстраницу. А, после благополучного ответа сервера – отобразить ее в соответствии с полученными заголовками и содержанием содержащегося в ней кода html и javascript. И, пожалуй, ничего более.
Попробуем и мы это сделать. Для этой цели создайте в том же самом каталоге, где находится сервер, обычный файл html, содержащий соответствующий код. Например, код можно взять с этого сайта (путем просмотра исходного кода, выделения и копирования). Но, для простоты и наглядности, я приведу здесь пример кода html, с которым мы будем работать далее:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="author" content="Sea" />
<title>Site</title>
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251"/>
</head>
<body>
<p>Hello World!</>
</body>
</html>
Сохраните этот код в файле с именем f.html. Для проверки, откройте его в браузере. Должна открыться страница с единственной надписью на ней:
Hello World!
В качестве заголовка страницы должна фигурировать надпись «Site».
Теперь стоит задача – прочитать этот файл программой-сервером и передать его клиенту (браузеру). Для этого, как обычно, можно использовать системные вызовы fopen, fgets. Соответствующая функция может иметь следующий вид.
Функция, читающая html-файл
// Функция, читающая html-файл
char *open_read_file(char *file_name) {
#define BS 64
size_t bytes_read;
char buf[BS+1], *str;
ssize_t count;
int i = 0;
FILE *fd = fopen(file_name, "r");
// Выделяем 1 байт памяти, для начала
if((str = (char*)malloc(1))==NULL){
perror("Allocation error.");
exit (0);
}
// Читаем файл до тех пор, пока не дойдем до его конца
while(!feof(fd)) {
i++;
//Считываем не более, чем BS байтов из файла за 1 итерацию цикла
if(fgets(buf, BS, fd))
// Добавляем еще BS байтов памяти перед тем, как записать считанные байты в массив str
if((str = (char*)realloc(str, i*BS+1))==NULL){
perror("Allocation error.");
exit (0);
}
strncat(str, buf, BS);
}
if (str == "") {printf("Not to read from file");}
fclose(fd);return str;
}
Вроде бы, по ней особых вопросов нет. Обратим лишь внимание на то, что на каждой итерации цикла, в ходе которого происходит построчное считывание (если длина строки не превышает величину BS), происходит увеличение выделенной динамической памяти под массив str. Однако, память здесь расходуется неэкономно.
Подумайте, почему. Подсказка: это связано с особенностями функции fgets, с одной стороны, и, в общем случае, с разными длинами строк в считываемом файле – с другой. Целесообразно сделать корректировку, оптимизирующую выделяемую память.
Примечание. Внимательно прочитайте об освобождении памяти при помощи функции free(). Если Вы при этом используете указатель на несуществующую память, дела могут кончиться достаточно плохо.
Как обычно, при использовании функций malloc(), realloc() ОБЯЗАТЕЛЬНО проверяем, успешно ли они выполнились. Если неуспешно, надо срочно прекращать работу, иначе плохо может быть.
После того, как закончена работа с массивом str, надо бы освободить память, расходуемую под него, при помощи функции
void free(char *str);
Реализуйте это в целесообразном месте программного кода.
III этап. Основная часть программы, открывающей файл html
Основная часть программы может выглядеть примерно следующим образом:
// Листинг 12. Виртуальный Эхо-сервер: отдача браузеру страницы html.
#include <sys/types.h>
#include <sys/socket.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <string.h>
// Описываем прототип функции чтения из html-файла
char *open_read_file(char *);
int main()
{
char message1[1024];
unsigned int sz;
int sock, listener;
struct sockaddr_in addr;
char buf[2048];
int bytes_read;
listener = socket(AF_INET, SOCK_STREAM, 0);
if(listener < 0)
{
perror("socket");
exit(1);
}
addr.sin_family = AF_INET;
addr.sin_port = htons(3425);
addr.sin_addr.s_addr = htonl(INADDR_ANY);
if(bind(listener, (struct sockaddr *)&addr, sizeof(addr)) < 0)
{
perror("bind");
exit(2);
}
listen(listener, 1);
int i =0; // Счетчик итераций сервера
while(1)
{i++;
sz=sizeof(addr);
sock = accept(listener, (struct sockaddr *)&addr, &sz );
printf ("\n");
if(sock < 0) {perror("accept"); exit(3);}
bytes_read = recv(sock, buf, 1024, 0);
// Печатаем в консоль разъясняющую информацию (номер итерации и протоколы, принятые от браузера)
printf("Server iteration: %d \n\n", i);
printf("Browser request: \n");
printf("%s \n\n", buf);
memset (buf, 0, sizeof(buf));
// Добавляем к сообщению сервера пустую строку
strncat(message1, "\n\r\n\r", 4);
char* buf = open_read_file("f.html");
printf("File sent by Server: \n");
printf("%s \n", buf);
// Формируем сообщение: Заголовки сервера + пустая строка + код html
strncat(message1, buf, strlen(buf)*sizeof(char));
// Отсылаем сообщение браузеру
send(sock, message1, strlen(message1) * sizeof(char)-1, 0);
if(bytes_read <= 0) break;
close(sock);
memset (message1, 0, strlen(message1) * sizeof(char));
}
return 0;
}
Запускаем Эхо-сервер
Так, что же. Запускаем в браузере, как и ранее. А, точнее, обновляем страницу с адресом
http://127.0.0.1:3425
И – вот что видим:
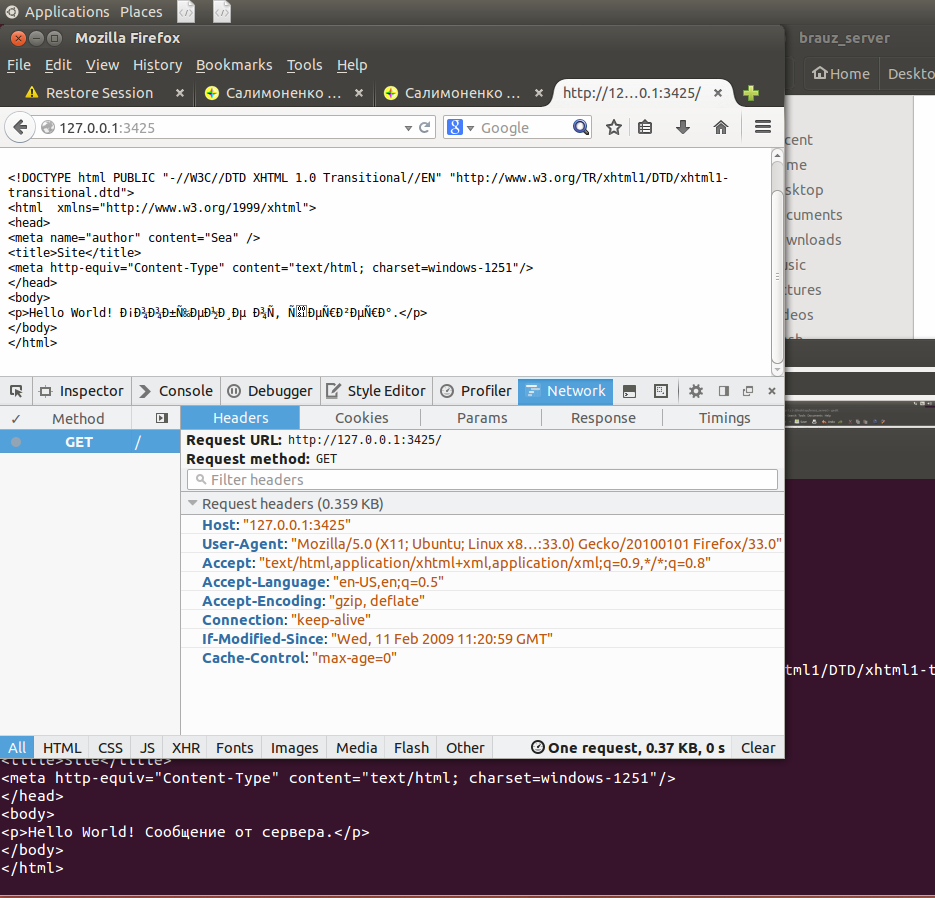
Да, браузер получил страницу, содержащуюся в файле f.html (кстати, сравните-ка то, что отобразилось в браузере и содержимое этого файла). Однако, текст отображается как-то странно: в виде кода html со всеми тегами.
Причина тому – мы не отослали от сервера ни одного заголовка – вот потому-то браузер и не знает, как обрабатывать эту страницу. Посему, он решил ее отобразить в наиболее простом виде, заключив все то, что получил от сервера, в тег <pre> (посмотрите исходный код страницы и убедитесь, что это так, в самом деле).
Действительно, заголовки запроса на рисунке есть, а заголовков ответа – нет ни одного.
Поэтому придется исправить ситуацию (иначе браузер так и не отобразит страницу, как положено). Следует добавить к сообщению сервера заголовки и пустую строку. Причем идти это должно ПЕРЕД основным сообщением (т.е. перед кодом html).
Т.е. нашему серверу надо объяснить браузеру – как именно следует обрабатывать присланную страницу – для этого и предназначены заголовки.
Например, они могут иметь следующий вид:
char message1[] = "HTTP/1.1 200 OK\nDate: Wed, 11 Feb 2009 11:20:59 GMT\nServer: Apache\nLast-Modified: Wed, 11 Feb 2009 11:20:59 GMT\nContent-Language: ru\nContent-Type: text/html;\ncharset=windows-1251\nConnection: close";
Эту строчку следует добавить в начало отсылаемого сообщения. Подумайте, как это сделать и реализуйте.
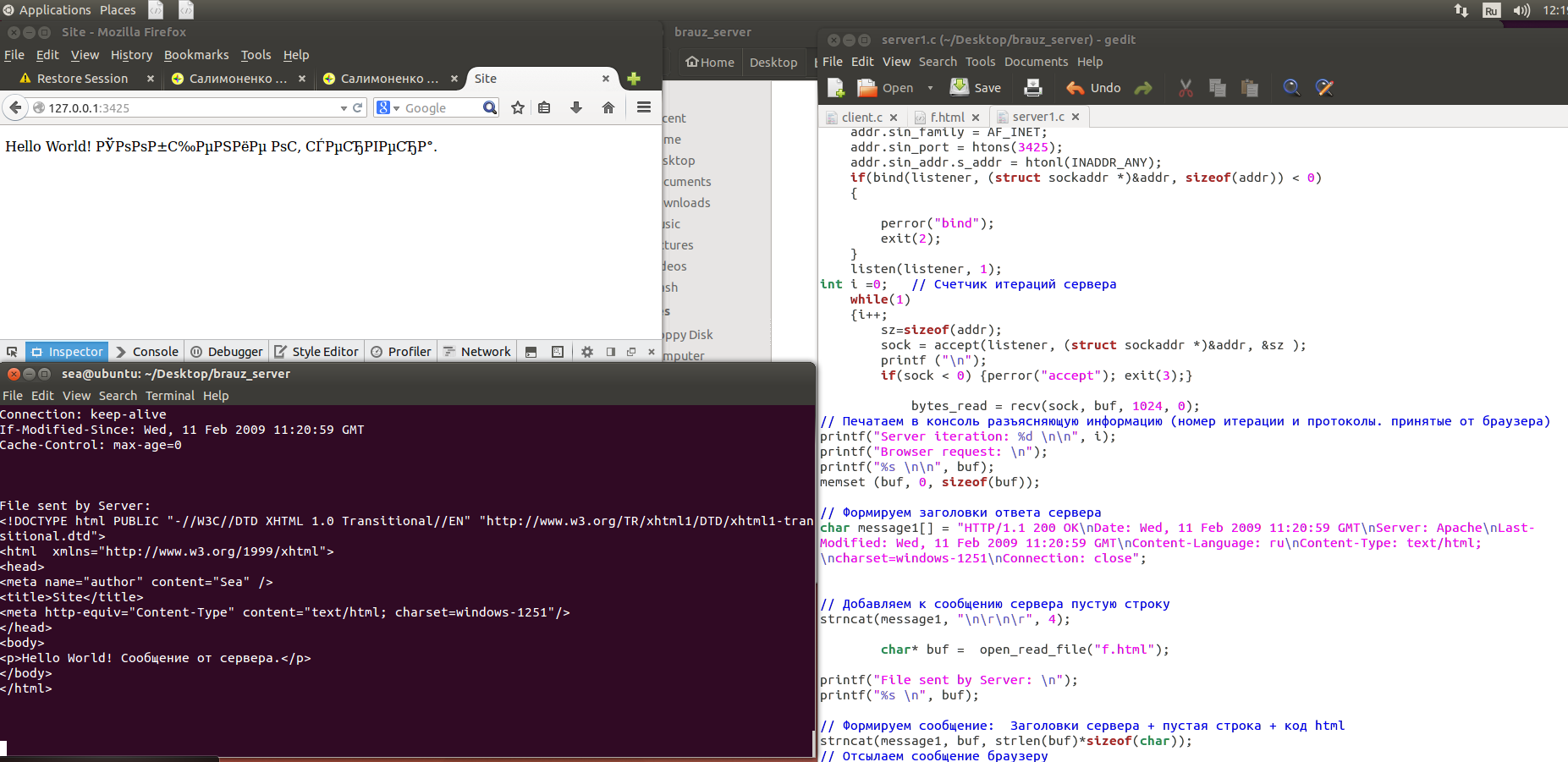
Если Вы сделаете все правильно, после запуска сервера и обновления страницы в браузере получится примерно следующее:
IV этап. Кодировки
Как видим, уже лучше: тегов html на странице уже нет, вместо них – появилась надпись
Hello World! Сообщение от сервера.
Естественно, заголовков, которые мы, вроде как, упаковали в начало сообщения, на самой странице также нет: их браузер прочитал, принял к сведению и не стал отображать на странице.
Однако, их можно посмотреть, если правой кнопкой мыши на странице браузера нажать
Исследовать элемент -> Сеть -> Обновить -> GET ->Заголовки
Анализируя заголовки ответа (сервера), можно видеть, что они представляют собой как раз те самые заголовки, которые мы упаковали в сообщение. Только перечислены они в обратном порядке: сверху идет последний, а в самом низу, наоборот – первый. Тогда как заголовки запроса (браузера), кстати, идут в хронологическом порядке, в том же самом, в котором и были отправлены.
Видим, что русскоязычный текст отображается нечитаемо. Причина тому – неверная кодировка.
Точнее, код html в файле
Потому, что, еще раз: у меня на сайте страницы выполнены в кодировке
Тогда как в Linux используется, по умолчанию, кодировка
f.html записан в неверной кодировке. Почему?Потому, что, еще раз: у меня на сайте страницы выполнены в кодировке
windows-1251. В метатегах, определяющих кодировку, также указана windows-1251.Тогда как в Linux используется, по умолчанию, кодировка
utf-8. Так как файл f.html создавался в Linux (в редакторе Gedit), соответственно, русскоязычный текст получил линуксовскую кодировку, т.е. utf-8. Ситуацию можно исправить двумя путями.
Первый путь – изменить кодировку на стороне клиента, выбрав в браузере
Вид -> Кодировка -> Юникод.
После чего браузер выдаст нам вполне читаемую страницу. Однако, так придется делать каждый раз при последующих обновлениях страницы (убедитесь в этом самостоятельно). Это – неудобно и хлопотно.
Второй путь – изменение кодировки на стороне сервера. В частности, следует в соответствующем заголовке, отсылаемом сервером, вместо
charset=windows-1251
указать
charset=utf-8.
Для чего следует внести небольшое изменение в программу.
Однако, этого – мало. Дело в том. что тогда получится противоречие между кодировкой, указываемой в заголовке сервера и кодировкой, указанной в файле f.html.
В самом деле, посмотрим внимательно на этот файл:
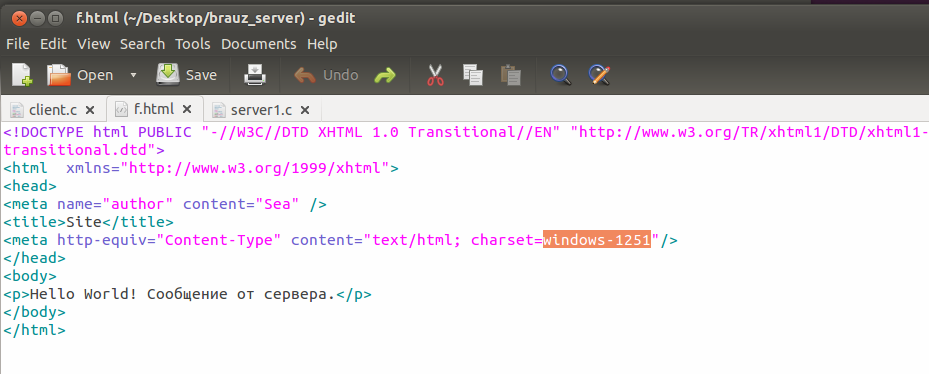
Видите место, выделенное оранжевым цветом? Так вот, представьте себе, ЧТО – делать браузеру? Сервер ему будет сообщать одну кодировку, а в метатеге он видит – совершенно другую. И вот здесь – каждый браузер может поступать, кто во что горазд. Кто-то может выбрать в итоге utf-8, а кому-то больше по душе будет windows-1251.
Чтобы избавить браузер от некорректной ситуации, необходимо исправить кодировку в файле f.html на utf-8. После чего – не забудьте сохранить этот файл.
Затем, убедившись, что сервер запущен (или запустив его вновь), обновив страницу в браузере, видим, что все стало хорошо: русский текст отобразился корректно и читаемо.
Итак, следует добиться, чтобы кодировка как в заголовках браузера, так и в метатеге вебстраницы была одинаковой. Ну, и, текст в файле, из которого сервер читает html-код для последующей отдачи браузеру – также должен быть записан в этой же кодировке.
Ибо просто указать кодировку в метатеге – это лишь формальная декларация, лишь информация для браузера – не более того. И если она не будет совпадать с истинной кодировкой текста вебстраницы, браузер, скорее всего, неправильно прочитает ее.
Итак, необходимо, для целей корректности, тройное совпадение кодировок:
- В заголовке ответа сервера,
- В метатеге вебстраницы,
- Кода html, содержащегося в файле с вебстраницей.
Кстати, видимо, по этой причине (т.е. не всегда – по недоразумению администраторов хостингов) некоторые серверы вообще не отдают никакой кодировки, не указывают ее в заголовках, полагаясь при этом полностью на вебмастеров – разработчиков html-страниц. Чтобы меньше создавалось некорректных ситуаций и, как следствие – меньше однотипных жалоб в службу поддержки.
И еще (тоже – кстати). Об этом нюансе «почему-то» практически нигде не пишут. Ну, по крайней мере, сколько я ни просматривал сайтов – как-то все поверхностно и, якобы, «со знанием» дела (особенно, на сайтах типа habrahabr.ru). Зачем, мол, говорить о, якобы, «очевидных» вещах (ну, да, конечно, зачем, когда толком не соображаешь, где звон, как говорится; когда – научился классы наследовать – и все, типа того, спец). А вещи-то, как видите, не так уж очевидные. Особенно, когда человек в первый раз сталкивается с этим. И это я еще не заговорил здесь о тонкостях кодировок, скажем, того же юникода… О том, как он, этот самый юникод, может, иной раз, оказать очень «полезную» услугу в плане взлома программы-сервера, к примеру.
V этап. Формируем GET-запрос
Попробуем поработать с нашим сервером, как с «настоящим». А именно – научимся формировать GET-запросы и обрабатывать их.
GET-запрос – это то, что идет в адресной (точнее, в командной) строке браузера после знака «?» («вопрос»). Такой запрос может выглядеть, в нашем случае, например, таким образом:
http://127.0.0.1:3425/?f=555
В данном случае, в строке
f=555
передается серверу значение переменной f, равное 555.
Сделаем такой запрос, нажмем клавишу Enter. И видим, что в консоль сервер вывел следующее:
Server iteration: 1
Browser request:
GET /?f=555 HTTP/1.1
Host: 127.0.0.1:3425
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:33.0) Gecko/20100101 Firefox/33.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
If-Modified-Since: Wed, 11 Feb 2009 11:20:59 GMT
Cache-Control: max-age=0
File sent by Server:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
….. (ну, и т.д.)
Видим, что в самой первой строчке параметров (заголовков), полученных сервером от браузера, фигурирует та самая строчка GET-запроса:
GET /?f=555 HTTP/1.1
Разберем ее подробнее.
Символы «GET» означают название одноименного метода передачи данных в запросе к серверу. В данном случае – метод GET.
Символ «/» (слеш) обозначает, как уже говорилось, корневой каталог нашего сервера (т.е. тот каталог, из которого он запущен).
Знак вопроса «?» означает начало строки параметров. Т.е. все то, что идет после него, является параметром (точнее, строкой параметров) и передается серверу вместе с заголовками. Знак равенства «=» служит разделителем между именем параметра и его значением. В данном случае именем параметра является f, а его значением – 555.
Кстати, если в GET-запросе следует передать не одно, а несколько параметров со значениями, то их пары разделяются символом «&», т.е. строка запроса будет иметь примерно следующий вид:
http://127.0.0.1:3425/?f=555&f1=777&f2=qwer
В данном случае серверу будут переданы следующие параметры:
f=555
f1=777
f2=qwer
Сервер может использовать полученные параметры в процессе работы над созданием, модификацией вебстраницы перед тем, как отдать ее браузеру.
Наконец, символы HTTP/1.1 обозначают наименование и версию протокола, предпочитаемого браузером.
Таким образом, извлекая из первого заголовка, полученного сервером, строку и параметрами и их значениями, распарсивая ее впоследствии нужным образом – сервер получает параметры, колторые ему могут пригодиться для обработки html-кода, который будет затем передан браузеру – в качестве ответа.
Рассмотрим GET-запрос, при помощи которого можно передать серверу, скажем, наименование цвета и размера шрифта:
http://127.0.0.1:3425/?p_color=green&p_size=14px&x=other
После того, как браузер передаст такой запрос нашему серверу, последний выведет в консоль следующее:
Browser request:
GET /?p_color=green&p_size=14&x=other HTTP/1.1
… и т.д.
Видим, что внутри заголовка содержится полностью вся строка GET-запроса, в том самом виде, в котором она была передана браузером.
Теперь задача – извлечь из первого заголовка переданные параметры:
#include <iostream>
#include <regex>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// #include <string>
// #include <fcntl.h>
// #include <unistd.h>
using namespace std;
#define N 10
char *b;
string str = "", ex, str_i[N];
int main()
{
str = "GET /?p_color=green&p_size=14&x=other HTTP/1.1\nHost: 127.0.0.1:3425\nUser-Agent: Mozil...";
if (str == "") cout<< "Not to read from file";
regex n("[\n\r]");
// Вырезаем из строки переводы строк (\n, \r)
str = regex_replace(str, n, "");
regex get_string("GET /\\?([\\s\\S]*?) HTTP/(.*)");
ex = regex_replace(str, get_string, "$1");
b = (char*)ex.c_str();
printf("\n\nAll GET-string: \n");
cout<<b<<endl<<endl; // Вывод на экран строки GET-запроса (без названий метода и протокола)
regex ampersand("(.*?)&(.*)");
// Распарсиваем строку GET-запроса и выводим пары "параметр = значение" построчно с использованием РЕГУЛЯРНЫХ ВЫРАЖЕНИЙ (для примера)
printf("'Param = znach': \n");
for(int i = 1; i < 8; i++) {
str_i[i] = regex_replace(ex, ampersand, "$1");
ex = regex_replace(ex, ampersand, "$2");
cout<<str_i[i]<<endl; // Вывод на экран
}
// Следует установить число итераций, равным расчетному числу пар, содержащихся в строке запроса, а не 8. (Число пар в данном случае равно 3).
// Распарcиваем первую пару "параметр=значение" с использованием strtokprintf("\nFirst pare 'parameter=value': \n");
char *s = new char[str_i[1].size() + 1];
strcpy(s, str_i[1].c_str());
string *param = new string[8];
param[1] = strtok(s, "=");
string *znach = new string[8];
znach[1] = strtok(NULL, "=");
cout << param[1]<<" "<<znach[1] << endl;
delete[] s;// Точно так же, создав цикл, следует распарсить и остальные пары "параметр=значение"
return 0;
Данный код использует регулярные выражения языка С++, поэтому следует компилировать его с использованием опции -std=c++11.
Вначале код распарсивает строку GET-запроса, разбивая ее на пары «Параметр=Значение». Распарсивание, для примера, выполнено при помощи регулярных выражений (хотя, в данном случае их применения является избыточным, см. ниже).
Затем производится распарсивание полученных пар (на примере первой пары).
В результате в консоль выводится следующее:
The GET-string:
p_color=green&p_size=14&x=other
'Param = znach':
p_color=green
p_size=14
x=other
x=other
x=other
x=other
x=other
First pare 'parameter=value':
p_color green
Видим, что в строковые массивы param[] и znach[], в качестве элементов с индексом «1» занесены параметр и значение первой пары GET-запроса, соответственно. Следует аналогичным образом распарсить и остальные пары.
Примечание. Использование функции strtok предпочтительнее, чем использование регулярных выражений по причине того, что первая работает быстрее (ну, должна, по крайней мере). Вообще, где есть возможность, следует избегать применения регулярных выражений, предпочитая им более простые функции.
Формирование атрибута стиля тега абзаца <p>
Далее, у нас должны получиться массивы param[] и znach[]. Следует написать программный код, анализирующий массив param[]. Если какой-либо из его элементов равен «p_color» или «p_size», то следует сформировать соответствуюшее свойство CSS (для всех остальных элементов запроса свойство CSS формировать НЕ НАДО). Например, если param[i] = “p_color”, то заполняем массив свойств CSS:
css[i] = param[i]+”: “+znach[i];
То же делаем для значения «p_size». Затем – объединяем все (в данном случае – два) элементы массива в один (в цикле), формируя атрибут style для html-документа:
css[0] = “style=’” + css[1] + “; “ + css[2] +”’”;
Теперь осталось вставить этот атрибут в тег абзаца <p>. Для этого целесообразно использовать регулярные выражения. В качестве шаблона, в учебных целях, можно использовать следующий:
“<p(.*?)>”
Конечно, данный шаблон является неполным. По идее, он требует доработки для возможности проверки наличия уже имеющегося атрибута style в теге абзаца. Кроме того, свойства color и/или font-size также могут существовать в этом теге, следовательно, также целесообразна соответствующая проверка. Можете доработать регулярное выражение с учетом этих проверок, если желаете. Оно, конечно, получится гораздо более сложным.
Если без доработки, то при аналогичном GET-запросе к серверу, если тег абзаца в html-файле уже будет содержать атрибут style, произойдет перезапись последнего. Естественно, при этом имевшиеся в нем все другие свойства (и их значения) в сообщении (в частности, в html-коде), которое будет отослано браузеру, исчезнут.
Примечание. Код html, модифицированный путем добавления атрибута style, сохранять в файле f.html не нужно. Но, при желании, Вы можете реализовать такую функциональность при условии, если в GET-запросе к серверу будут содержаться символы
save=YES
Выводы
Итак, что получилось? Получился простой локальный (или виртуальный – как правильно назвать) HTTP-сервер. Который, правда, способен делать лишь одно: считывать html-код из вебстраницы, находящейся на компьютере, дополнять ее заголовками и пустой строкой и – передавать браузеру в требуемом виде.
Этот сервер доступен по IP-адресу 127.0.0.1. Однако, он является доступным (по крайней мере, в локальной сети) и с других компьютеров.
Почему? Потому, что в качестве адреса клиента в программе указано
Это означает, что любой компьютер локальной сети, обратившийся к этому серверу (точнее, обратившийся к интерфейсу, привязанному в этой сети к открытому порту
INADDR_ANY.Это означает, что любой компьютер локальной сети, обратившийся к этому серверу (точнее, обратившийся к интерфейсу, привязанному в этой сети к открытому порту
3425), сможет открыть в браузере страницу, html-код которой содержится в файле f.html.А это, в свою очередь, открывает возможности для взаимодействия компьютеров в локальной сети между собой. Конечно, разработанная программа нуждается в существенной доработке – для того, чтобы его можно было бы назвать именно СЕРВЕРОМ. Надо, скажем, добавить обработку ошибок, обработку нештатных ситуаций в разных условиях (которых может быть, на самом деле, очень и очень много). Кроме того, следует добавить обработку параметров, передаваемых браузером – как в момент запроса страницы, так и после этого. Это, в частности, параметры GET и POST запросов. Отдельный разговор – динамическое формирование страницы, с учетом баз данных.
Ну, а в итоге, если всё-всё-всё это сделать – мы и получим один из вариантов уже имеющихся серверов, будь то Apache, Nginx, Denwer или еще что. Повторюсь, едва ли стоит это делать на практике, но, понимать такую возможность, а также опробовать хотя бы самое начало, азы ее реализации – следует ясно и отчетливо.
Самое главное, после выполнения этого задания должно быть ясно понятно, что сервер – это не какая-то мифическая совокупность программных кодов, которая «устанавливается на хостинг и как-то там работает, что-то делая», а вполне себе простая (идеологически) программа, которая только-то и делает – что принимает ТЕКСТОВЫЕ запросы-команды от клиентов, например, от браузеров в формате протокола HTTP (или другого протокола). В соответствии с этими запросами – открывает файл(ы), анализирует и обрабатывает их (и файлы, и сами запросы) и, наконец, отправляет клиенту ответ. Который, как правило, включает в себя тот соответствующий html-код. HTTP-запросы клиентов и ответы сервера передаются при помощи, в частности, транспортных протоколов, например, ТСР. Вот и все.
Задание для самостоятельной разработки
- Выполните всю последовательность действий – согласно данному заданию, приведенному на этой странице. Следует детально разобрать работу и особенности программы.
- Выполнить корректировку (оптимизацию) объема памяти, выделяемой массиву при чтении файла
f.html(см. выше). - Освободить память, занимаемую переменной
strпосле того, как эта переменная более не потребуется. - Реализовать обработку параметров GET-запроса при открытии страницы
f.html. Например, пусть будет такой GET-запрос:
http://127.0.0.1:3425&/p_color=green&p_size=14px&x=other.
Добавьте в программу сервера код (в виде дополнительной функции), который будет изменять цвет абзаца (т.е. цвет текста, который содержится в теге <p>) на тот, который содержится в параметре p_color запроса (в данном случае – цвет green); размер шрифта на тот, который содержится в параметра p_size запроса. Для этого программа должна, перед тем, как отдать файл браузеру, добавить в тег абзаца стиль, устанавливающий зеленый цвет, т.е. тег абзаца должен будет иметь примерно такой вид: <p style=”color:green; font-size:14px;”> … Текст абзаца … </p>
Это можно сделать, например, используя регулярные выражения (собственно говоря, как раз для подобных целей и разработана эта технология). После чего проверьте работу программы: при указании разных цветов и размеров шрифта в адресной строке, после нажатия клавиши Enter (т.е. очередном запросе страницы) формат текста в браузере должен изменяться соответствующим образом.
- Если в запросе переданы еще и другие параметры, помимо
p_colorилиp_size, они не должны применяться к стилю абзаца. - Ограничить число итераций цикла, в котором происходит распарсивание строки GET-запроса, числом передаваемых пар «параметр=значение».
- Распарсить все пары
«параметр=значение»(как это сделано на примере 1-й пары). Можно сконструировать более сложный GET-запрос, содержащие и какие-либо иные параметры. - Определить число пар
«параметр=значение»и указать это число в качестве размерности строковых массивовstring param[]иstring znach[], а также массиваcss[]. - Реализовать «обычную» функциональность сервера для целей открытия именно того файла html, который указан в запросе браузера. Т.е. если GET-запрос имеет вид:
http://127.0.0.1:3425/f.html?p_color=green&p_size=14&f2=qwer, то должен открываться файл, указанный в нем (перед знаком вопроса). При указании имени другого файла сервер должен, соответственно, открывать этот (другой) файл.
С уважением, Салимоненко Д.А.